Performance
Rigorous benchmarking supports the team’s development activities by providing rapid feedback on complex changes and a regular benchmark process allows the team to discover and address performance regressions during day-to-day development, well in advance of any releases.
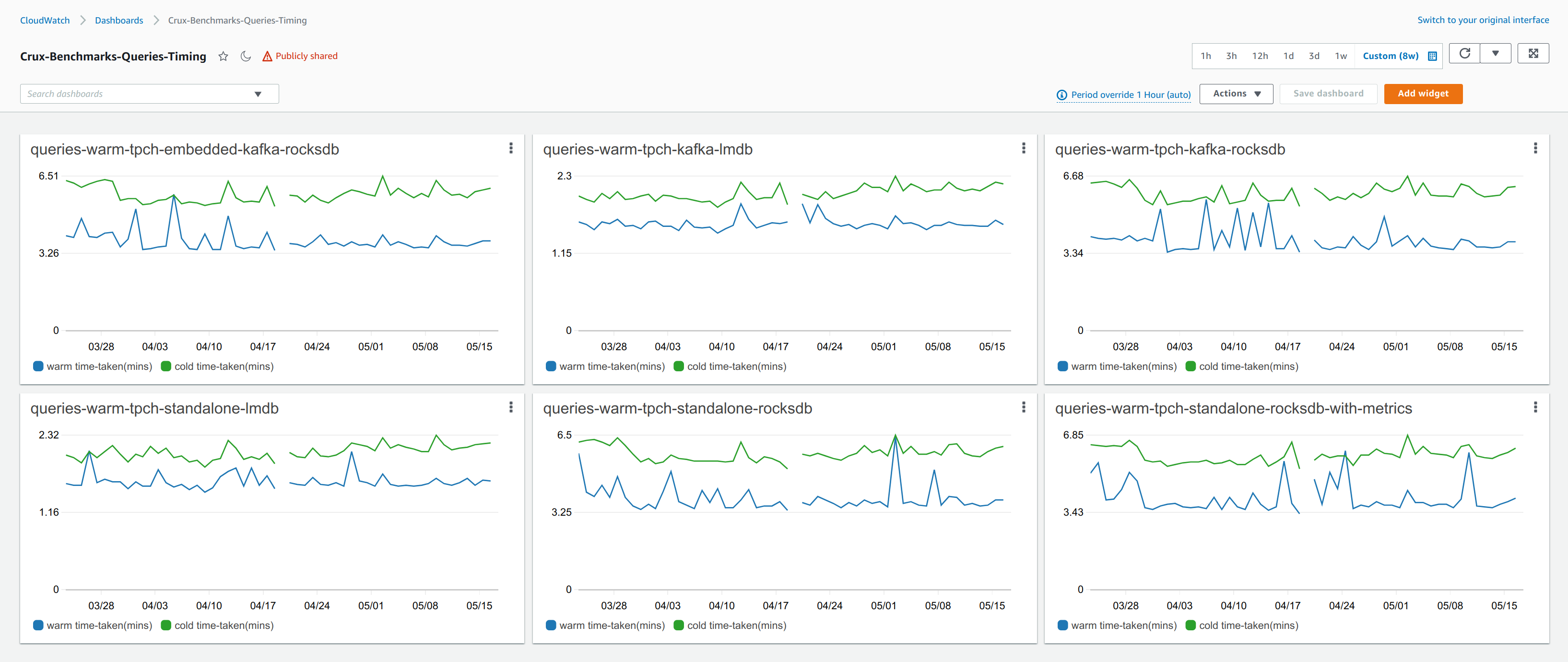
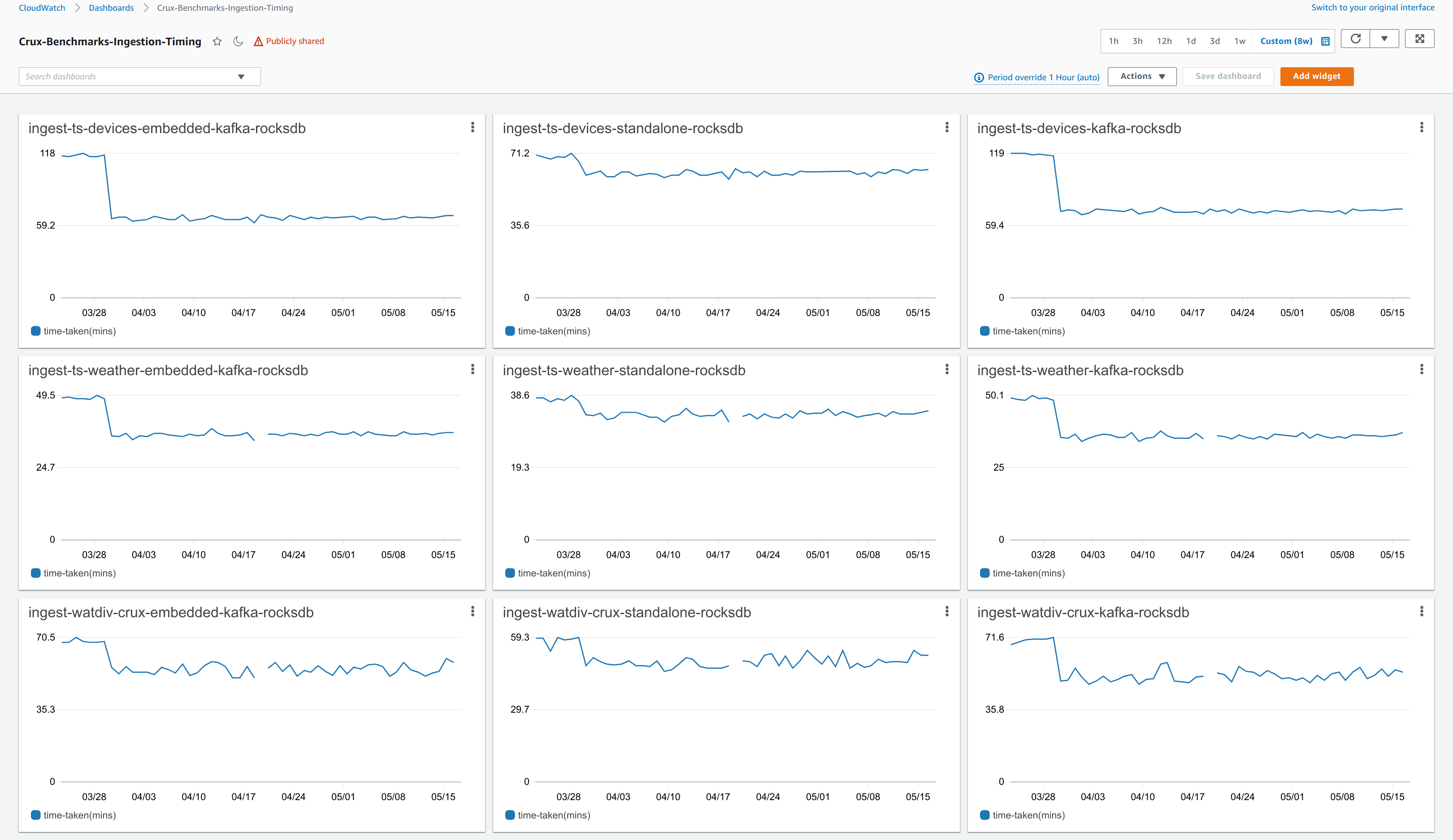
The bench sub-project contains a number of benchmarking suites that are run nightly on standard AWS infrastructure (m5.xlarge instances via CloudFormation) to support regression testing of new development and validate all performance improvement changes.
These suites cover a wide range of analysis at a variety of scale factors, including: graph query performance, bitemporal query performance, ingestion performance (throughput & latency), and disk usage.
Officially published benchmark results are forthcoming, but in the meantime please feel welcome to explore bench independently and get in touch if you need any assistance.
For an example of independent benchmarking by the community, see the "XTDB Connector" performance analysis by the Linux Foundation’s Egeria project, which compares XTDB against an existing JanusGraph Connector.
TPC-H
See the TPC-H test fixture for details.
WatDiv SPARQL Tests
WatDiv has been developed to measure how an RDF data management system performs across a wide spectrum of SPARQL queries with varying structural characteristics and selectivity classes.
Benchmarking is performed nightly against the WatDiv test suite. These tests demonstrate comprehensive RDF subgraph matching. Note that XTDB does not natively implement the RDF specification and only a simplified subset of the RDF tests have been translated for use in XTDB. XTDB generates Datalog, which shares many of the same properties as SPARQL, directly from the SPARQL definitions.
Subgraph matching is a fundamental kind of graph query and is a common mechanism for computing query results in SPARQL: RDF triples in both the queried RDF data and the query pattern are interpreted as nodes and edges of directed graphs, and the resulting query graph is matched to the data graph using variables as wildcards.
The diversity and scale of subgraph matching in the WatDiv tests provides a particularly helpful measure of end-to-end performance across many dimensions.
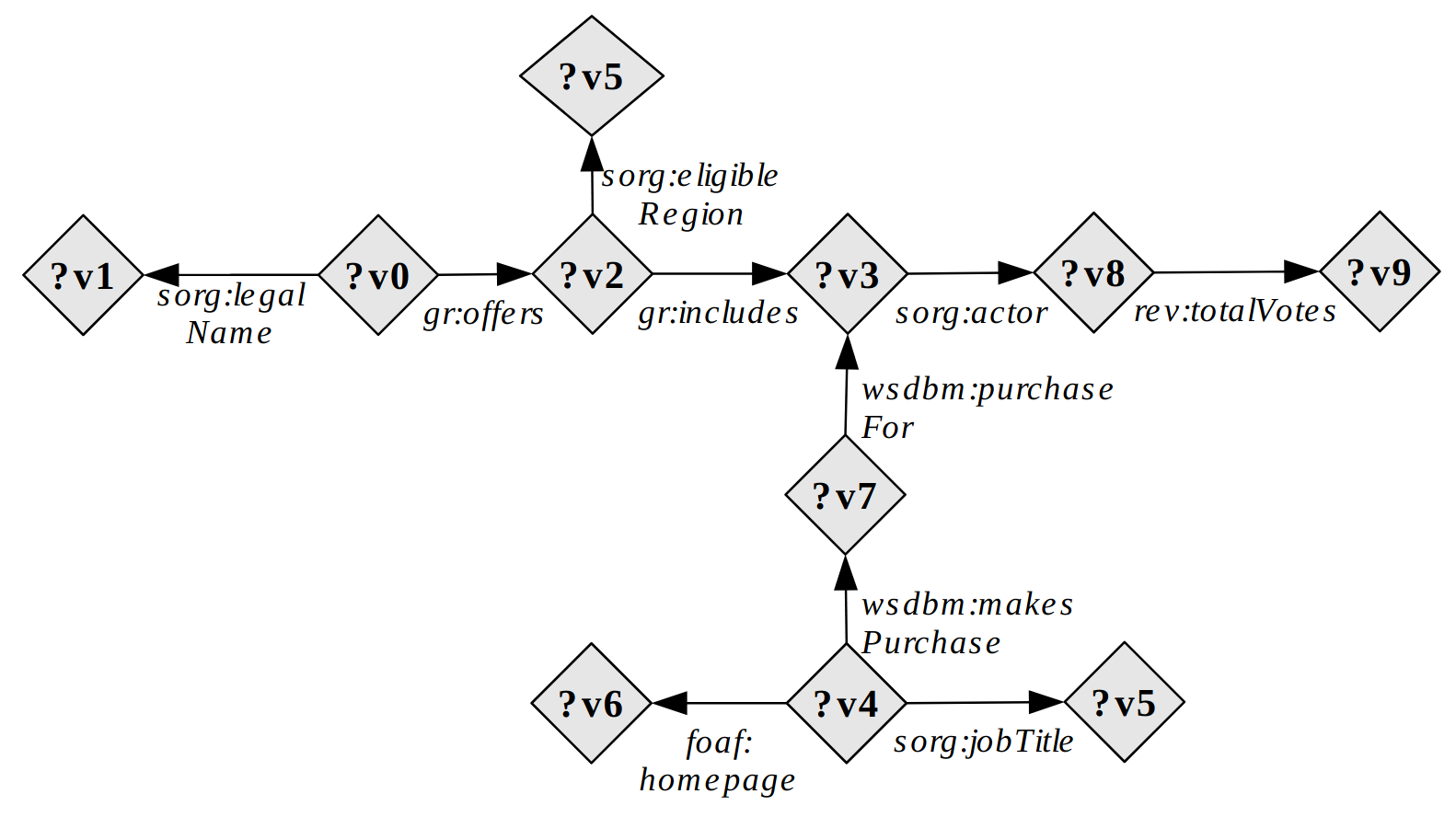
SELECT ?v0 ?v3 ?v4 ?v8 WHERE {
?v0 sorg:legalName ?v1 .
?v0 gr:offers ?v2 .
?v2 sorg:eligibleRegion wsdbm:Country5 .
?v2 gr:includes ?v3 .
?v4 sorg:jobTitle ?v5 .
?v4 foaf:homepage ?v6 .
?v4 wsdbm:makesPurchase ?v7 .
?v7 wsdbm:purchaseFor ?v3 .
?v3 rev:hasReview ?v8 .
?v8 rev:totalVotes ?v9 .
}
DataScript
XTDB’s test suite incorporates a large number of DataScript's query tests, demonstrating extensive functional coverage of DataScript’s Datalog implementation.
LUBM Web Ontology Language (OWL) Tests
The Lehigh University Benchmark is developed to facilitate the evaluation of Semantic Web repositories in a standard and systematic way. The benchmark is intended to evaluate the performance of those repositories with respect to extensional queries over a large data set that commits to a single realistic ontology. It consists of a university domain ontology, customizable and repeatable synthetic data, a set of test queries, and several performance metrics.
Racket Datalog
Several Datalog tests from the Racket Datalog examples have been translated and re-used within XTDB’s query tests.
Specifically, from https://github.com/racket/datalog/tree/master/tests/examples
-
tutorial.rkt
-
path.rkt
-
revpath.rkt
-
bidipath.rkt
-
sym.rkt